

BIDS, Goodly Labs | UX, Data analytics & visualization | 12 weeks Liberating the Archives —
Data Analysis and Visualization for Legal Researchers
Introduction
In the era of big data, we assume everything can be accessed from some digital databases. However, there seems to be a gap between digital transformation and one of the most critical construction - the Supreme Court. In our program with Berkeley Institute of Data Science(BIDS) and Goodly Labs proposed a data-driven solution to build a web platform that provides textual database, NLP analysis and data visualization.

Presentation at the Berkeley Devision of Data Science
Problem Research
Current Supreme Court Transcript lack accessibility and analyzing tools to public researchers. They are all PDF files, which disallows searching function within the web page. The current database is only chronologically ordered, but lack classification information such as justice background, keywords search, and case categories.

https://www.supremecourt.gov/oral_arguments/argument_transcripts/2019/18-6135_nlio.pdf
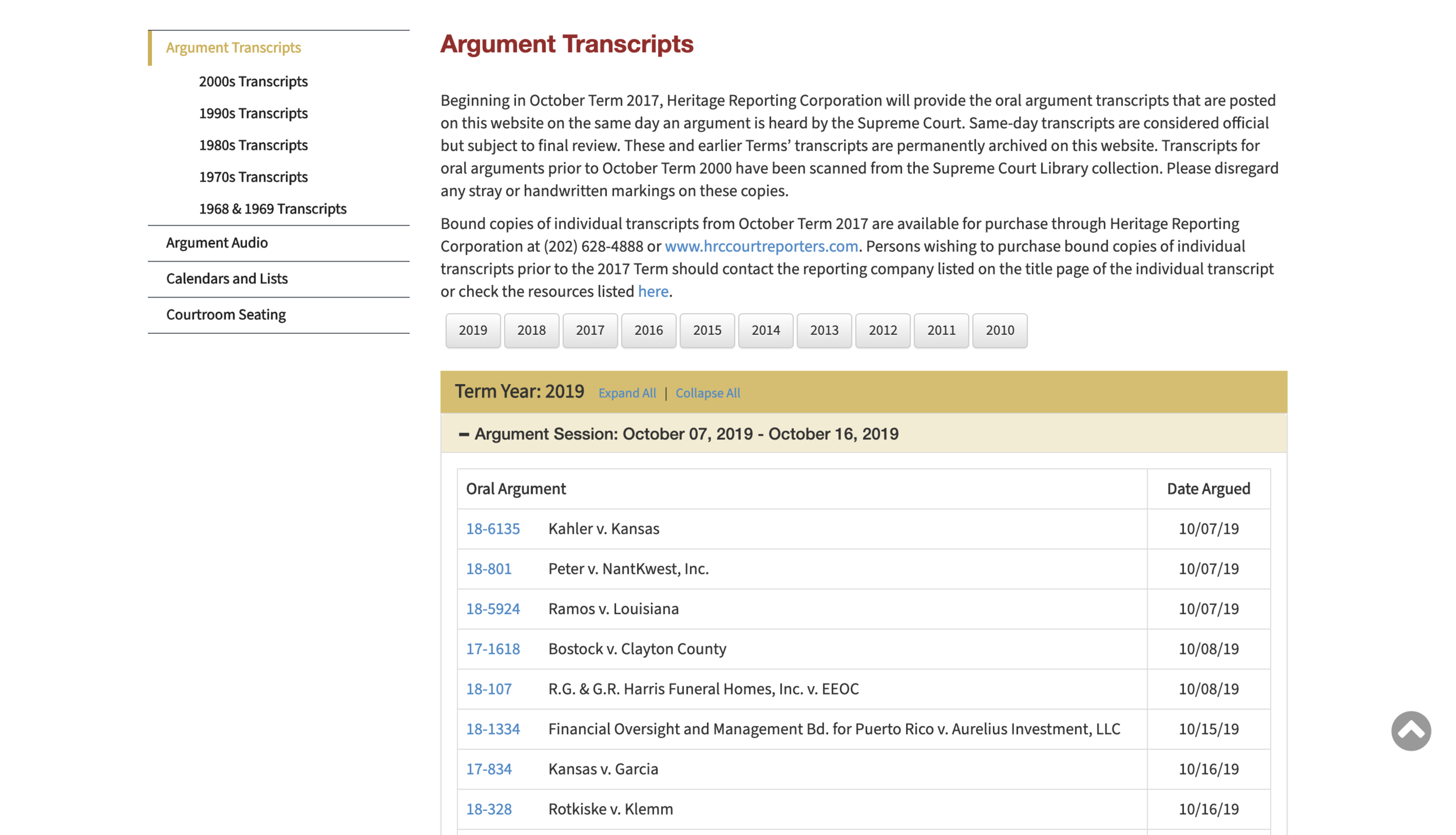
https://www.supremecourt.gov/oral_arguments/argument_transcript/2019
User Interview
Our goal is to figure out what information is needed for legal researchers and how to best present it and our targeting users are the legal scholars and researchers. We studied websites about judiciary data in United States, Europe and China. We also interviewed professor Michael Levyand and a graduate student Ran Wang from Berkeley Law School on their opinions.
What are the most useful queries to extract in Supreme Court Transcript?
Time, Category, Judge Name, Petitioner, Respondent, Lower Court, Advocates, Votes.
What analysis is useful for legal researchers?
Predictive model on opinions based on judges’ profile
Similar Algorithms: “Predicting judicial decision of the European Court of human rights result: a NLP perspective”
Acts/Bills
What old acts/bills is mentioned in the transcript?
When are these acts/bills passed and what level(state, national..) are they?
Sentiments and tones
Relation between current event and case type
Are judges swayed by current events?
Judges profile analysis
How many cases did he/she deal?
What are the types of these cases?
What are the opinions of the cases?
What’s the political leaning of the judges?
“What are some good examples of data presentation?

Percentages of Different Verdicts for
1. Different Types of Crimes 2. Different Regions

https://www.lexisnexis.com/en-us/products/lexis-advance.page
Frequency of Acts Mentioned in Different Court
Database Design


Data Categories
Time, Topic, Title, Judge - Home Page Filtering Options
Speech Table, Person Table - Sentimental and Ideological Analyzer
Geographical and topic trends data - Data Visualization
github: https://github.com/pratibha99/supreme-court-transcripts

Database design demo
Data Visualizations

Geographical data demo
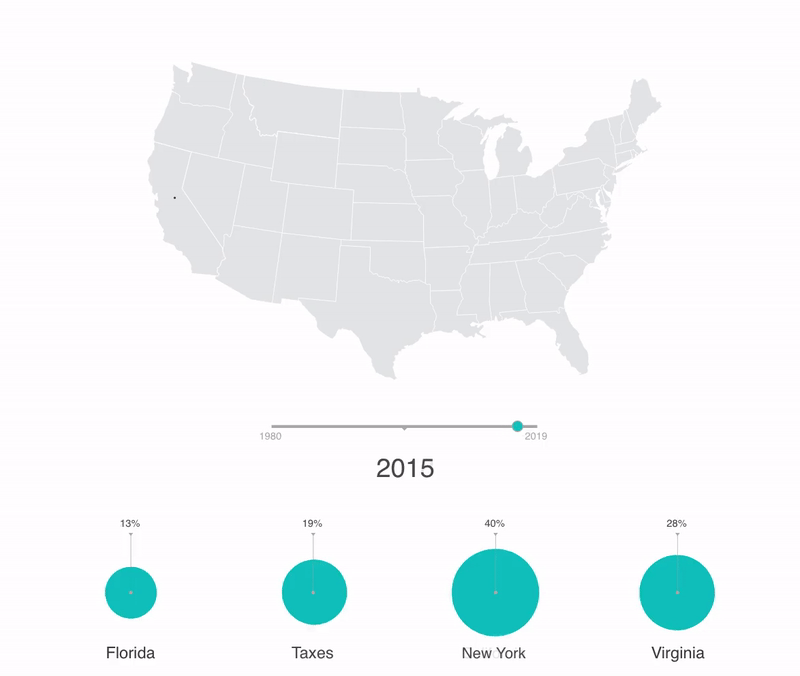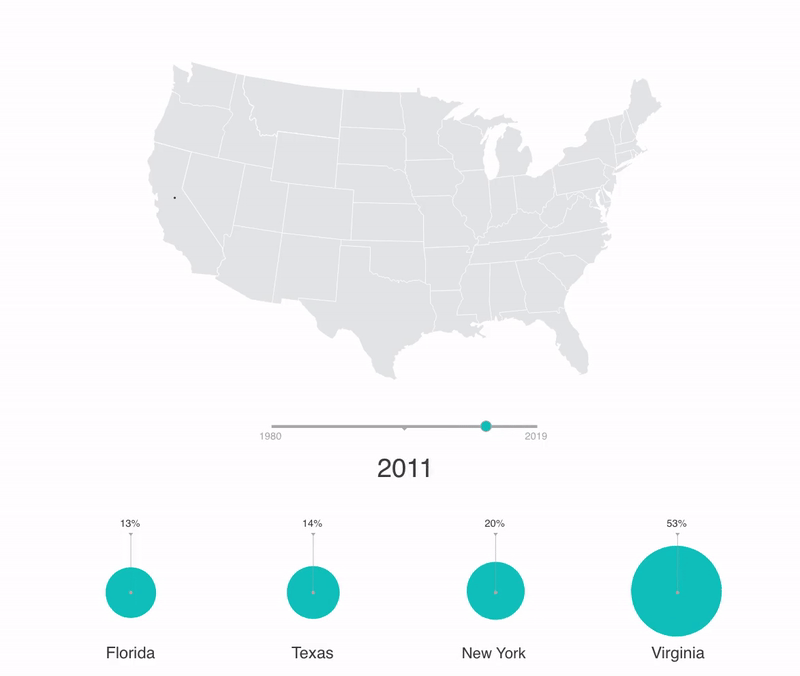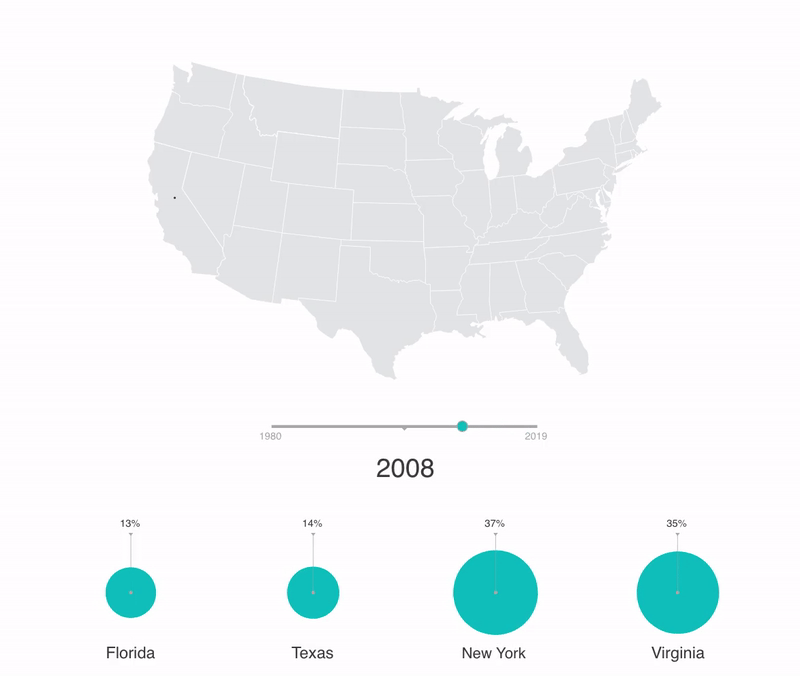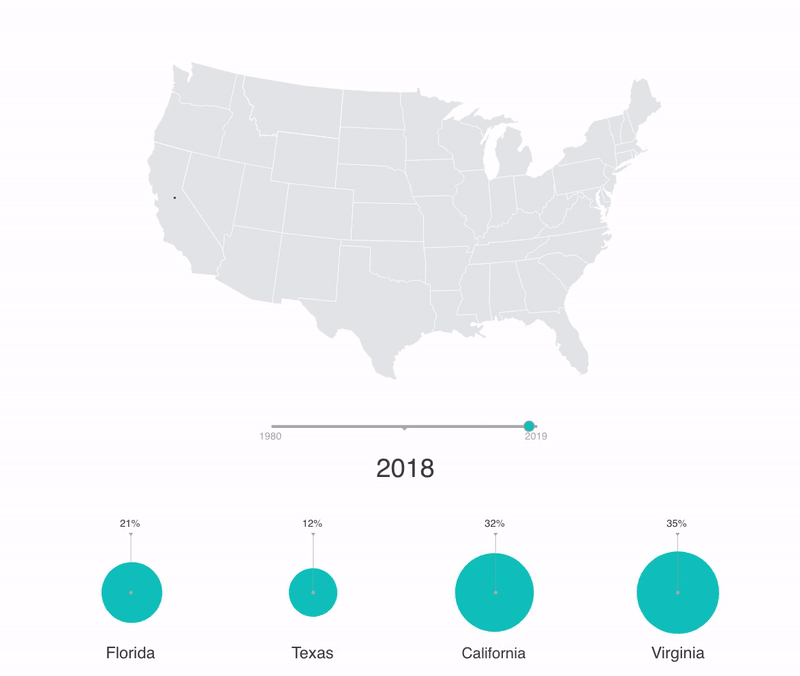
Geographical data demo


Correlation between Supreme Court Cases and Social Topics demo

Political Leaning and Votes of the Justices demo

Sentimental Score of the Oral Argument demo
Next Step
Next, we want to work on the technical side of the projects and realize more ideas envisioned by Professor Michael Levyand, such as the predicative model. We are looking forward to publishing the website and help legal researchers.